SPSS分析方法
1. 数据录入
(1) 变量视图
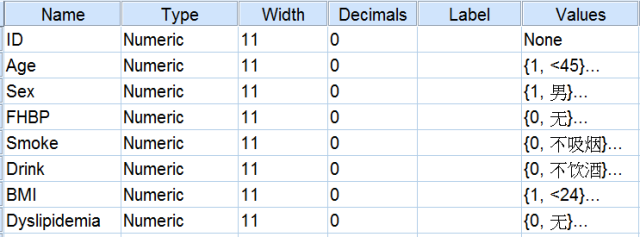
(2) 数据视图

2. 倾向性评分匹配
选择Data→Propensity Score Matching,就进入倾向性评分匹配的主对话框。
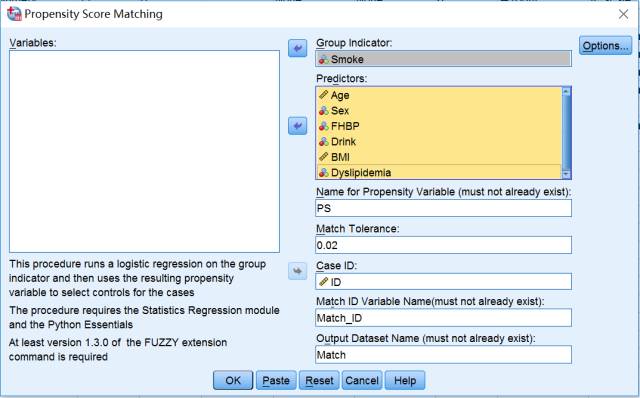
将分组变量Smoke放入Group Indicator中(一般处理组赋值为“1”,对照组赋值为“0”);将需要匹配的变量放入Predictors中;Name for Propensity Variable为倾向性评分设定一个变量名PS;
Match Tolerance用来设置倾向性评分匹配标准(学名“卡钳值”),这里设定为0.02,即吸烟组和不吸烟组按照倾向性评分±0.02进行1:1匹配(当然,卡钳值设置的越小,吸烟组和不吸烟组匹配后可比性越好,但是凡事有个度,太小的卡钳值也意味着匹配难度会加大,成功匹配的对子数会减少,需要综合考虑~~~);
Case ID确定观测对象的ID;Match ID Variable Name设定一个变量,用来明确对照组中匹配成功的Match_ID;Output Dataset Name这里把匹配的观测对象单独输出一个数据集Match。
3. Options设置
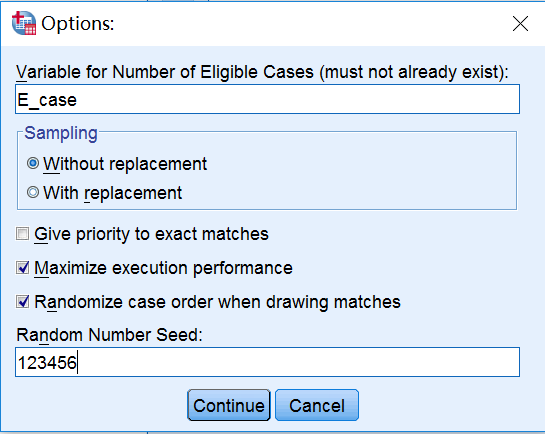
Variable for Number of Eligible Cases设定一个变量,用来明确病例组中某一个观测对象,在对照组中有多少个观测对象满足与其匹配的条件,比如说病例组有一个观测对象PS=0.611,对照组可能有一个0.610,一个0.612。
Sampling默认为不放回抽样。
Give priority to exact matches 优先考虑精确匹配,也就说病例组有一个观测对象PS=0.611,对照组也应该找到一个0.611。
Maximize execution performance 执行最优化操作,即系统会综合考虑精确匹配和模糊匹配(基于设定的卡钳值范围内匹配),系统默认勾选。
Randomize case order when drawing matches整个匹配过程中,如果对照组有多个满足匹配条件的观测对象,那么SPSS会默认随机将其与病例组观测对象匹配。但是因为SPSS默认每次操作给对照组的随机数字不同,所以如果不特殊设定,每次实际匹配成功的对子是不一样的,也就说这一次对照组A匹配给病例组B,下一次就可能匹配给病例组C。所以需要自行设置,并且在Random Number Seed设定一个随机数种子,确保匹配过程可以重复。
结果解读
1. 匹配结果
表2以吸烟(1=吸烟;0=不吸烟)为因变量,以需要调整的变量为自变量构建logistic回归模型(表2),求出每个研究对象的PS值。
表2. logistic回归模型
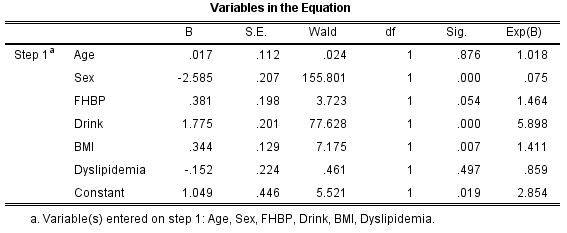
表3显示,精确匹配45对,模糊匹配114对,共计匹配成功159对。
表3. 匹配结果
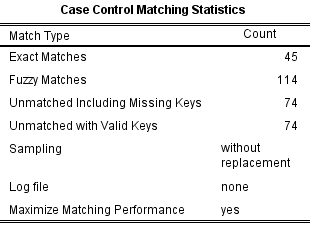
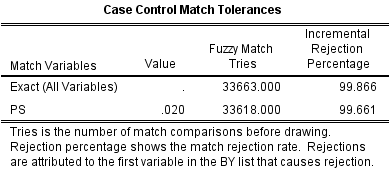
表4主要是匹配过程。首先是精确匹配(即PS完全一致),匹配33663次,大约1%匹配成功;其次在精确匹配成功的前提下,进行PS的模糊匹配(PS±0.02,即最开始设定的卡钳值为0.02),匹配33618次,大约3.3%匹配成功。
表4. 匹配容许误差
2. 匹配后数据库
输出的数据集Match中出现之前设定的几个新变量:E_case表示对照组中有几个符合匹配条件的观测对象(如图,吸烟组ID=2,有2个对照组观测对象符合匹配条件);PS是基于logistic回归模型计算出的倾向性评分;match_id表示匹配成功的ID。

3. 数据库整理
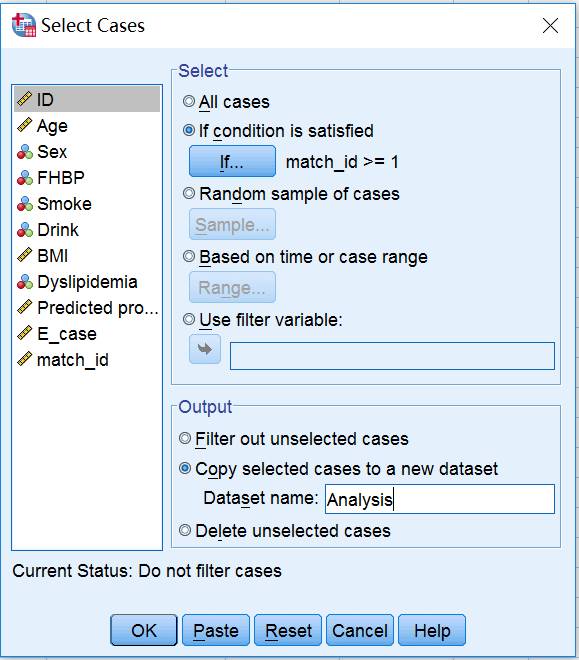
A. 筛选匹配成功的对子:选择Data→Select Cases→If condition is satisfied:设定match_id≥1,筛选出匹配成功的对子→Output中输出新的数据集Analysis。
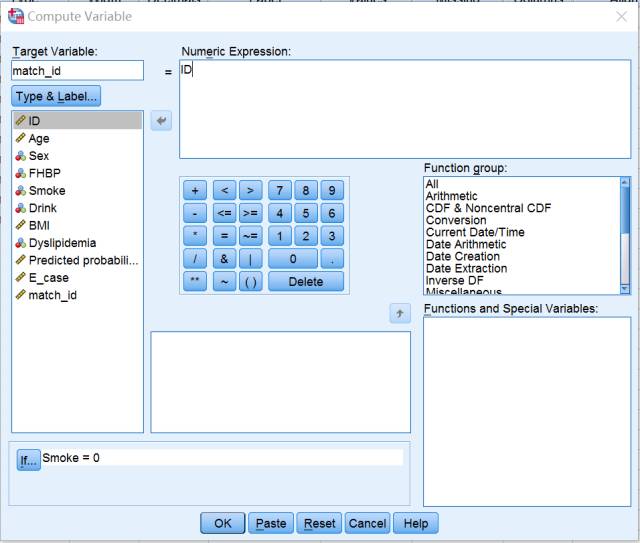
B. 确定匹配成功标识:match_id为吸烟组和不吸烟组相互匹配成功的ID,这里将不吸烟组match_id变量转换为ID变量,这时候相同的match_id即为匹配成功的对子。具体操作:将Analysis数据集中,不吸烟组match_id替换成ID编号:Transform→Compute Variable→if smoke=0, match_id=ID→OK
C. 选择Data→Sort cases→按照匹配标识match_id排序(相同的match_id即为匹配成功的对子)→OK→Save(你的鼠标手一定要点保存!!!)

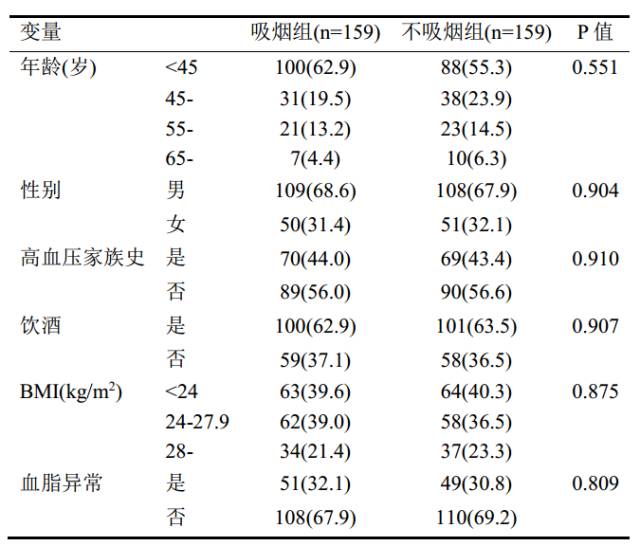
倾向性评分匹配就搞定了,再来看看匹配情况。表5显示,原吸烟组233例,最后共有159例匹配成功(这次我们限定PS≤0.02,但可根据实际情况选择合适的限定,增加匹配成功数!),各匹配因素在两组间都均衡可比。
表5. 两组基线情况比较(匹配后)
总结和拓展
PSM一般分为三种类型:
1、PS最邻近匹配:是PSM最基本的方法,即直接从对照中寻找一个或多个与处理组个体PS值相同或相近的个体作为配比对象。本次我们就采用的是这个方法。
2、分层PSM:PS最邻近匹配尽管可以使协变量总体趋于平衡,但不能保证每个协变量分布完全一致。可以根据某个重要变量(如性别)分层后,分别对每层人群进行PS最邻近匹配,然后再将配比人群合并,这样就可以保证该重要变量在组间分布完全一致。
3、与马氏配比结合的PSM:PSM与马氏配比结合后可以增加个别重点变量平衡能力,实现过程比较复杂。
对于1:m PS匹配和与马氏配比结合的PSM,目前SPSS22及以上版本自带的PSM并不能实现,后面会介绍基于SAS软件复杂倾向性评分匹配。
参考文献
李智文, 张乐, 刘建蒙,等. 倾向评分配比在流行病学设计中的应用[J]. 中华流行病学杂志, 2009, 30(5):514-517.
“科研加油站”“号内搜索”“护你健康”“号内搜索”“科研加油站”
觉得好看,请点这里👇返回搜狐,查看